前言
因为这几天访问DeepSeek的时候总是遇到服务繁忙,加上蒸馏后参数量大大减小,已经可以部署在本地了
这篇文章记录了我部署的过程,如果你也希望本地使用DeepSeek,希望它能够帮到你😉
ok那我们开始吧
前期准备
检查显存大小
对于Win用户
在powershell中输入如下命令:
nvidia-smi |
会得到类似的output
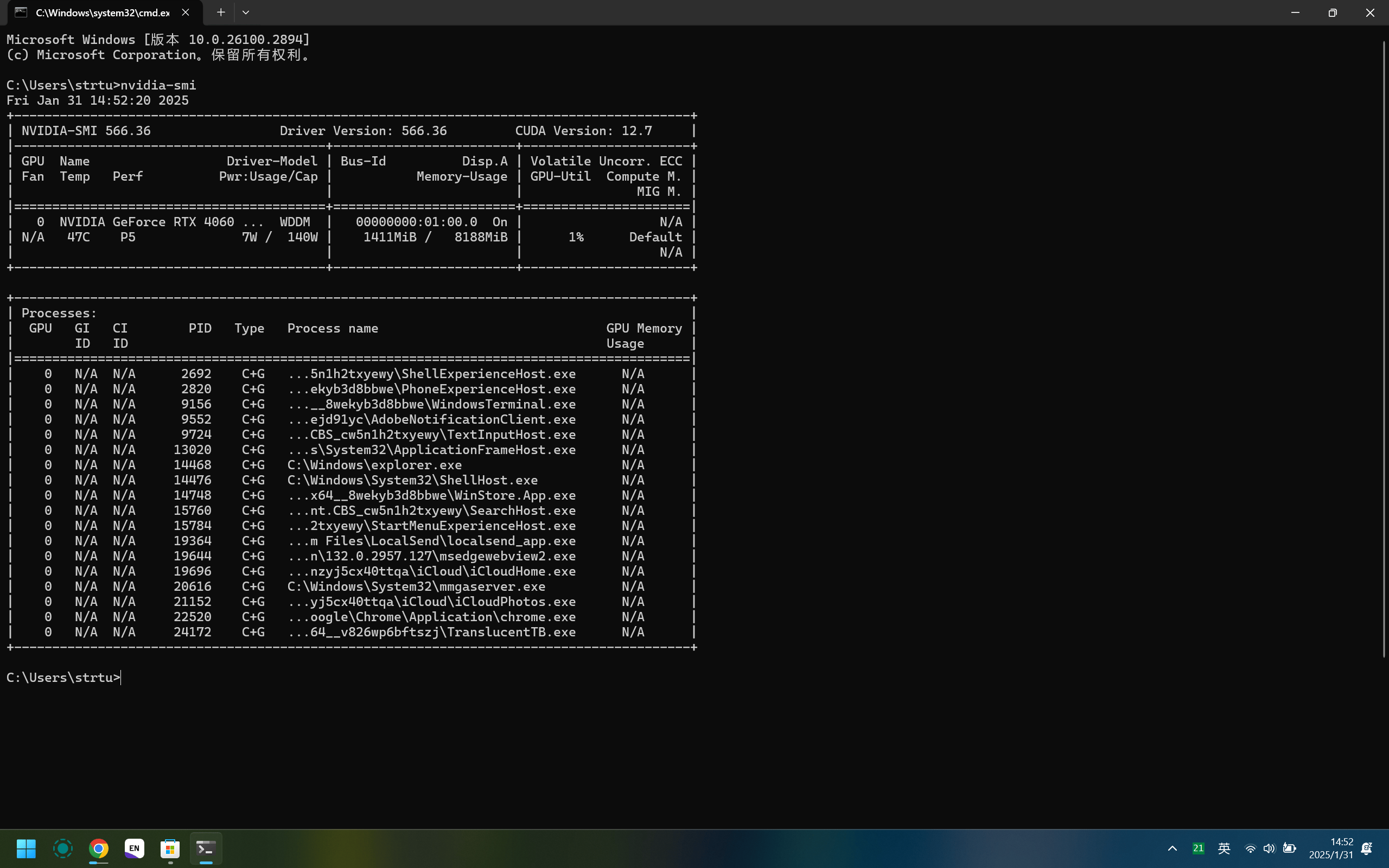
可以看到我的显存是8188MB
请记住你的显存大小,这是我们选择模型参数量大小的重要参考因素
对于MacOS用户
在[设置-关于本机]界面,查看搭载的芯片组型号
如果是M系列芯片,由于引入了统一内存架构,内存即为显存,可以看到我的内存是8GB
如果是Intel架构的芯片,则本教程不适用,因为装不上Ollama框架

安装Ollama框架
访问Ollama 官网 ,根据你的操作系统选择对应的安装包进行下载。
因为服务器在国外,下载速度会很慢,可尝试如下方案:
1.启动多线程下载
在chrome的地址栏输入如下命令:
chrome://flags/#enable-parallel-downloading |
使Parallel downloading的状态为Enable
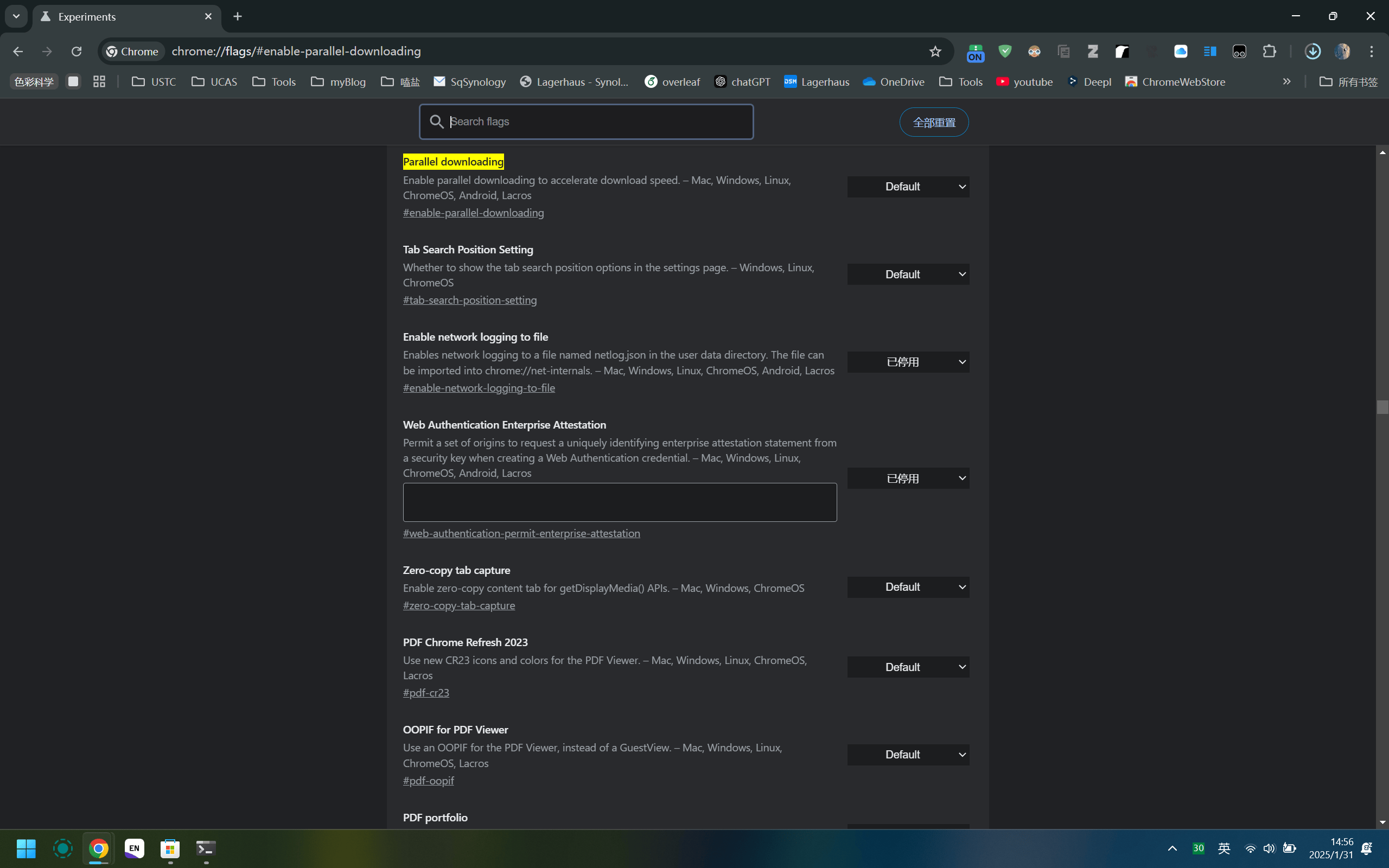
启动前:
启动后:
2.选择合适的科学上网节点
部分美国节点配合多线程下载可以跑到25MB/s,Amazing!
下载完成后,会默认安装至C盘,约占用10G空间
为了验证Ollama成功安装,在PowerShell中输入如下命令:
ollama -v |
如果安装正确,会输出Ollama的版本号,如下图所示

模型部署
选择模型
我们今天要部署的Distill版本,是在阿里的QWEN千问和META的LLAMA基础上再训练实现的蒸馏版本
(btw,满血版的deepseek-R1基于deepseek-v3再训练实现,具有671B参数,理论上起码需要350G以上显存才能够部署)
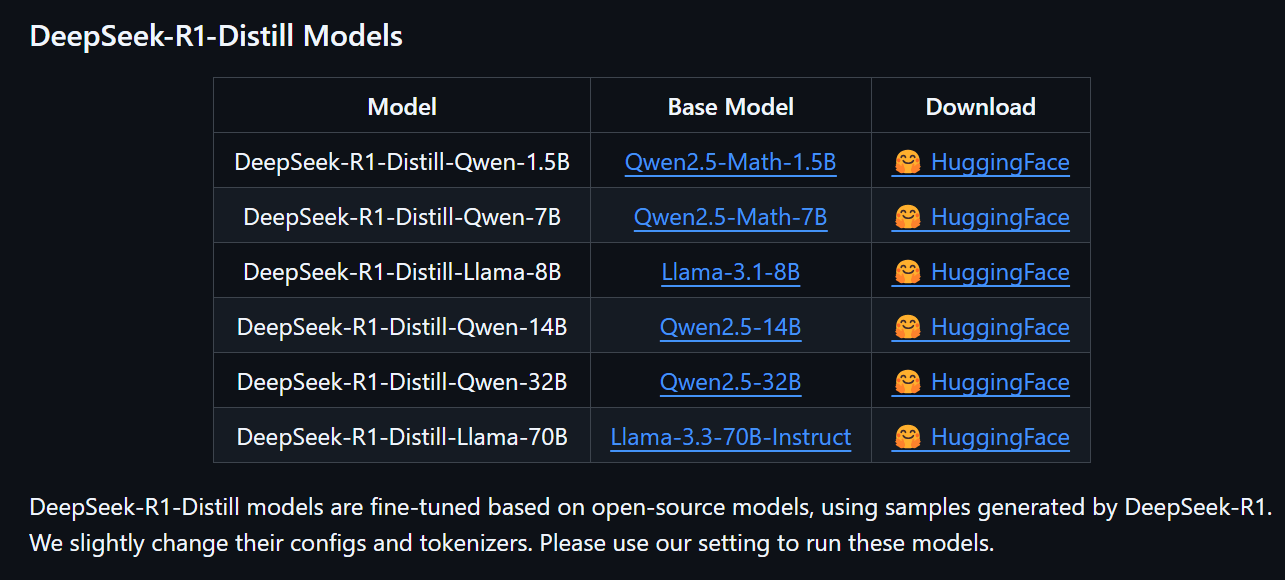
一般来说,8G显存可以部署8B级别模型;24G显存可以刚好适配到32B的模型,请根据自身电脑硬件配置来选择合适的模型版本
下载模型
根据显存大小,我选择下载8B参数的量化模型:
ollama run deepseek-r1:8b |
如果想下载其他参数量的,只需要将8B修改为新的参数值
如选择 32B 版本,则改为ollama run deepseek-r1:32b
耐心的等待下载即可
开始对话
使用如下命令启动DeepSeek:
ollama run deepseek-r1:8b |
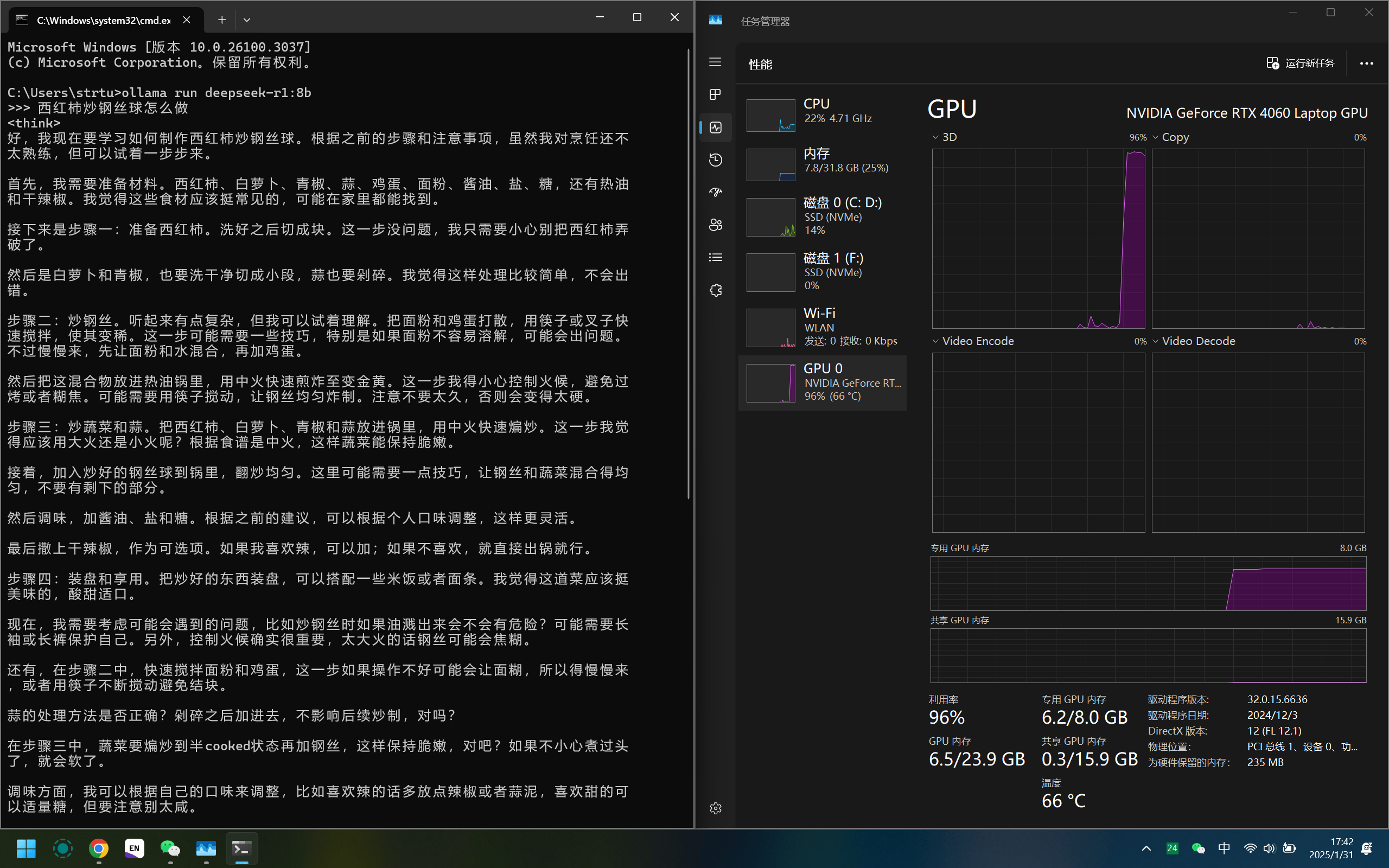
即可与DeepSeek对话:
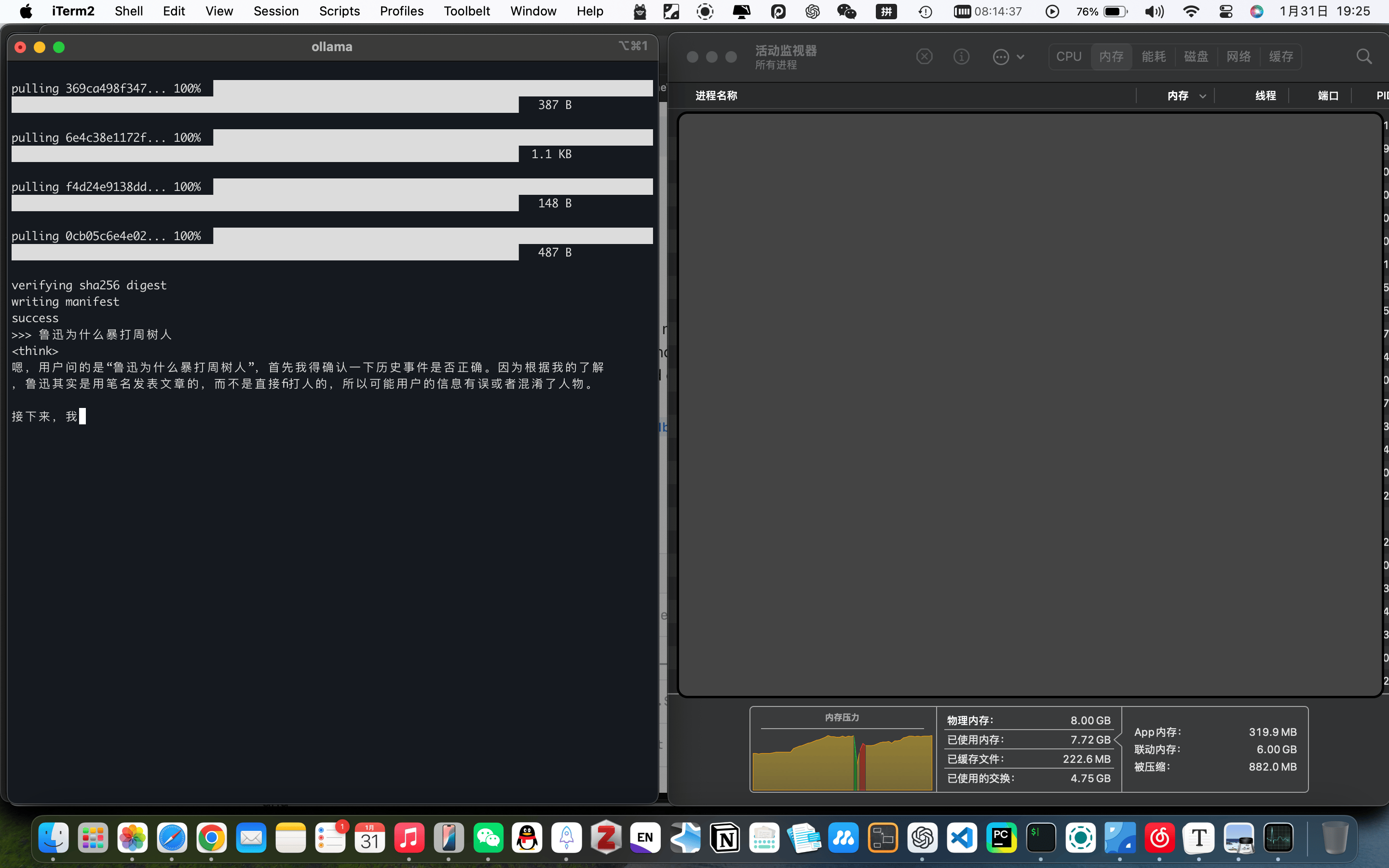
可以看到显存只用了6GB
对于MacOS用户,大同小异
M1的GPU基本被4060按在地上摩擦🤣(不过最近看很多youtuber使用MacMiniM4组成的集群跑LLM,效果也不错)
进阶使用
部署Open webUI
如果你认为命令行过于简陋,可以尝试部署Open WebUI框架来引入更简明的交互界面
1.安装Docker
我们进入docker 官网,根据自己电脑的操作系统下载对应的版本的DockerDesktop
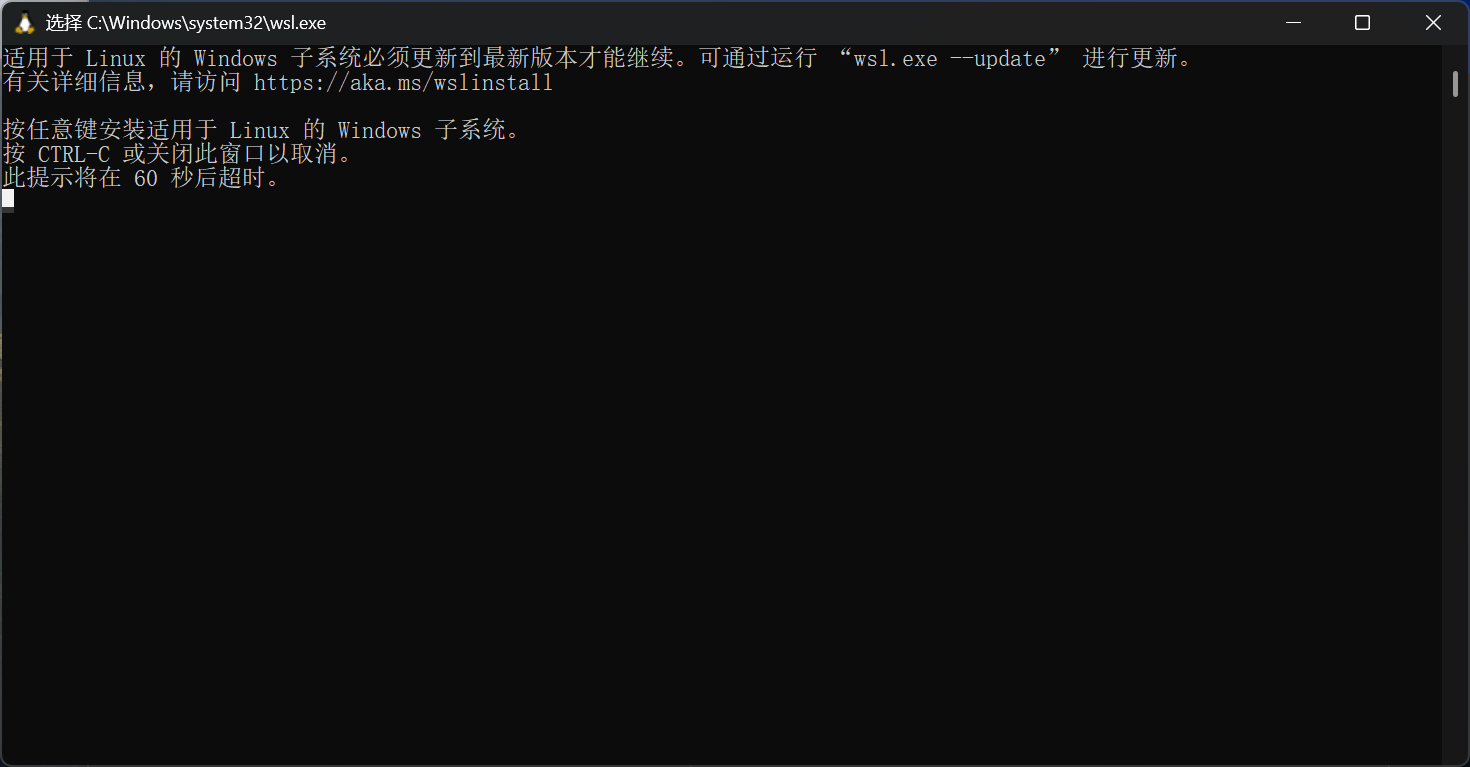
下载完成后,你可能会被提醒需要更新子系统,因为服务器在海外,请使用科学上网的方法更换节点
完成更新后打开DockerDesktop

点击右下角Terminal,输入下面命令,然后等待安装完成
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
因为GFW正式DNS污染+SNI阻断了docker.com及其相关域名,你仍然需要确保自己是在科学上网的环境
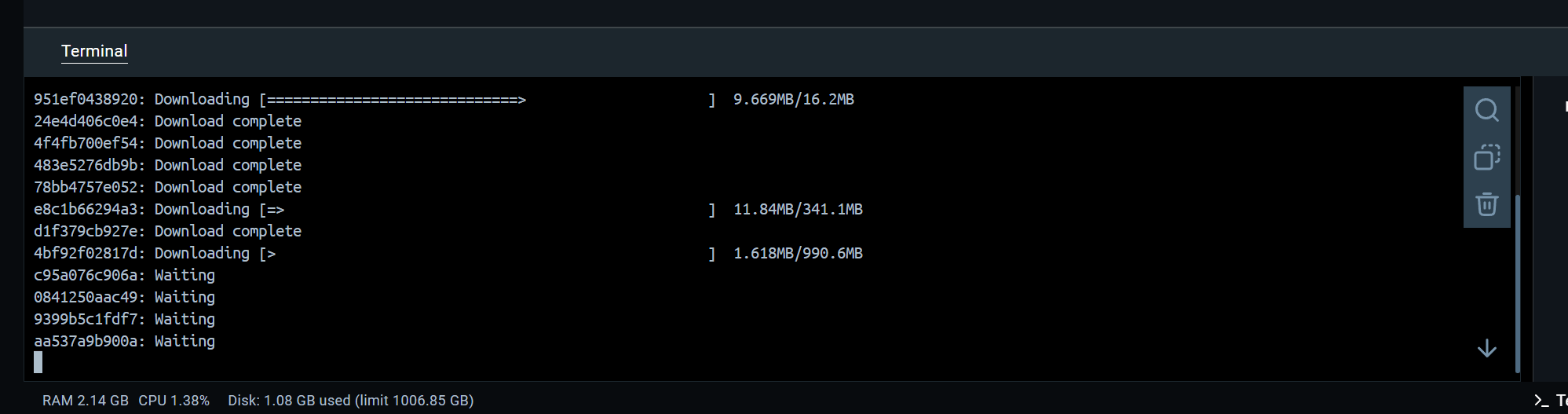
这一步耗时很久,需耐心等待
可以看到我们已经pull了open webui
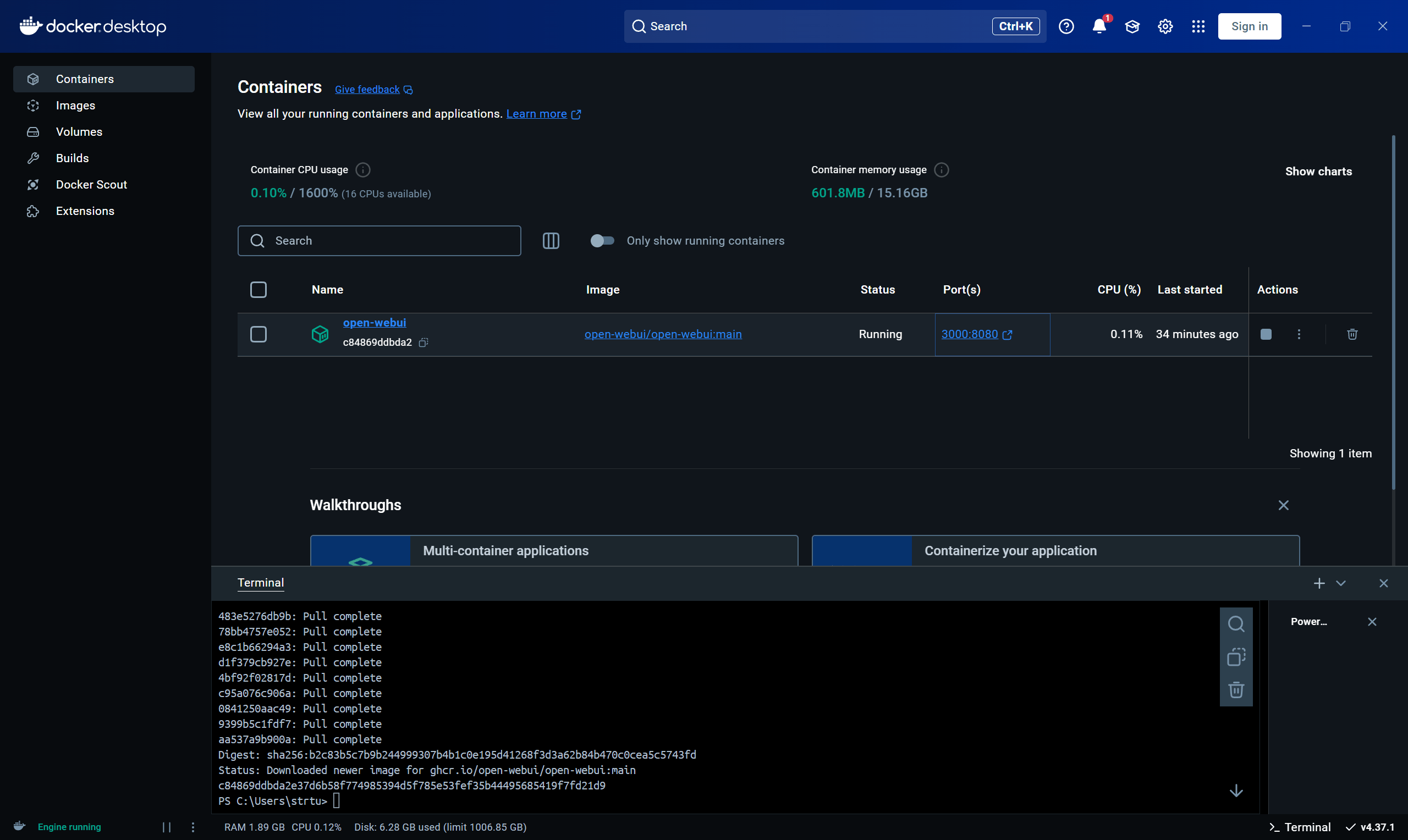
我们之前已经将本机的端口3000映射到容器内的端口8080,这意味着可以通过访问 http://localhost:3000来访问运行在容器内的服务
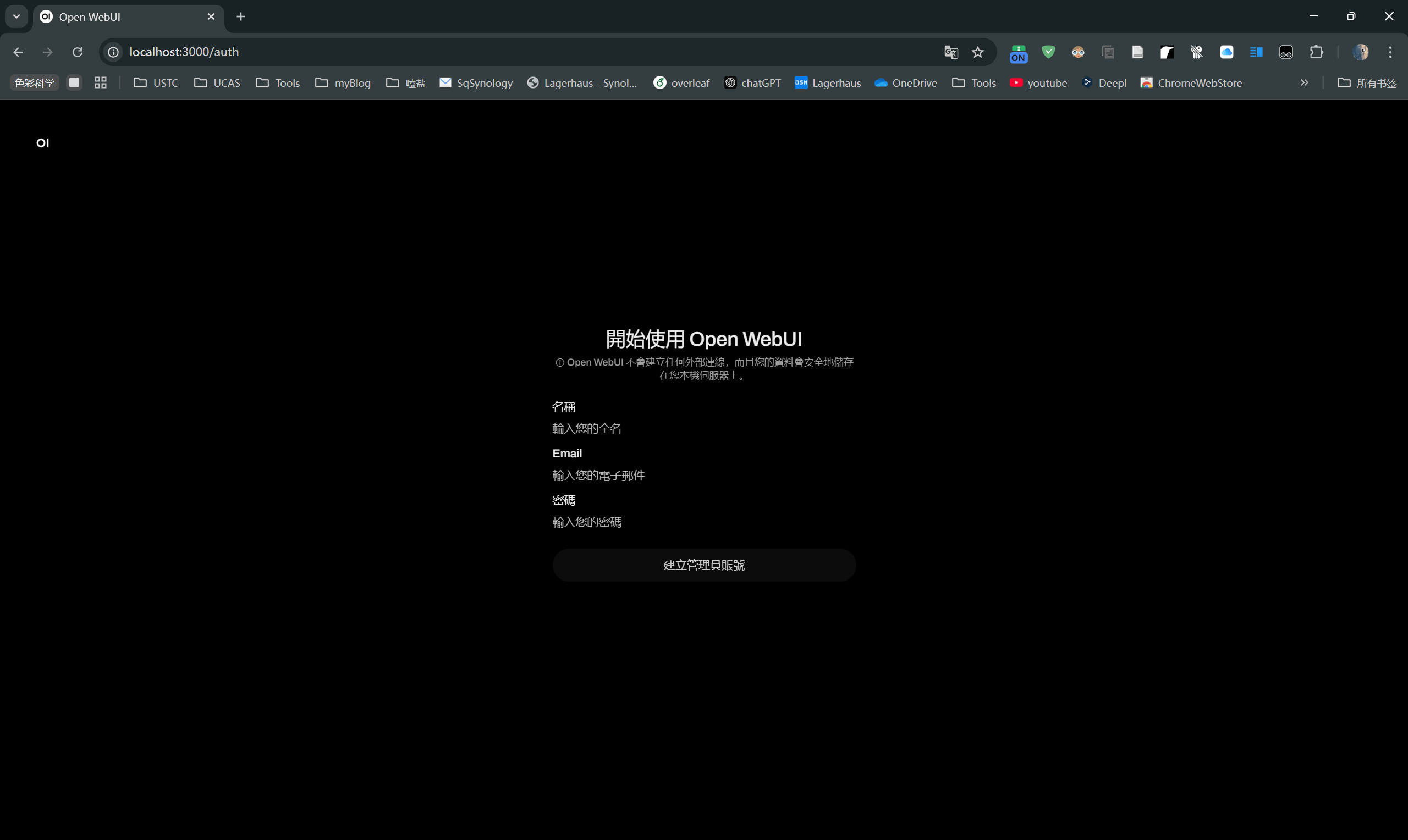
根据提示完成初始化
完成后可以选择已经pull到本地的模型
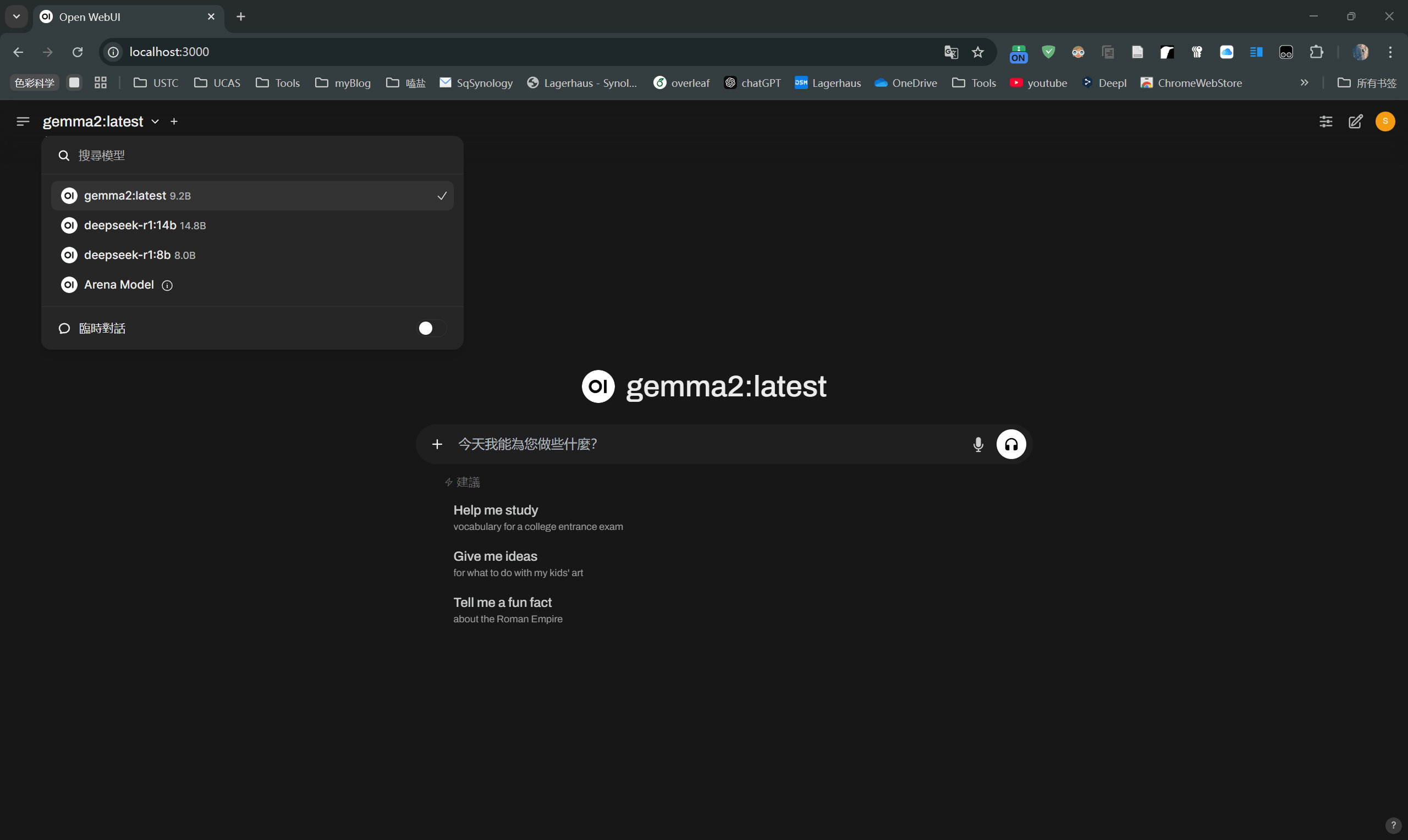
我觉得它很蠢
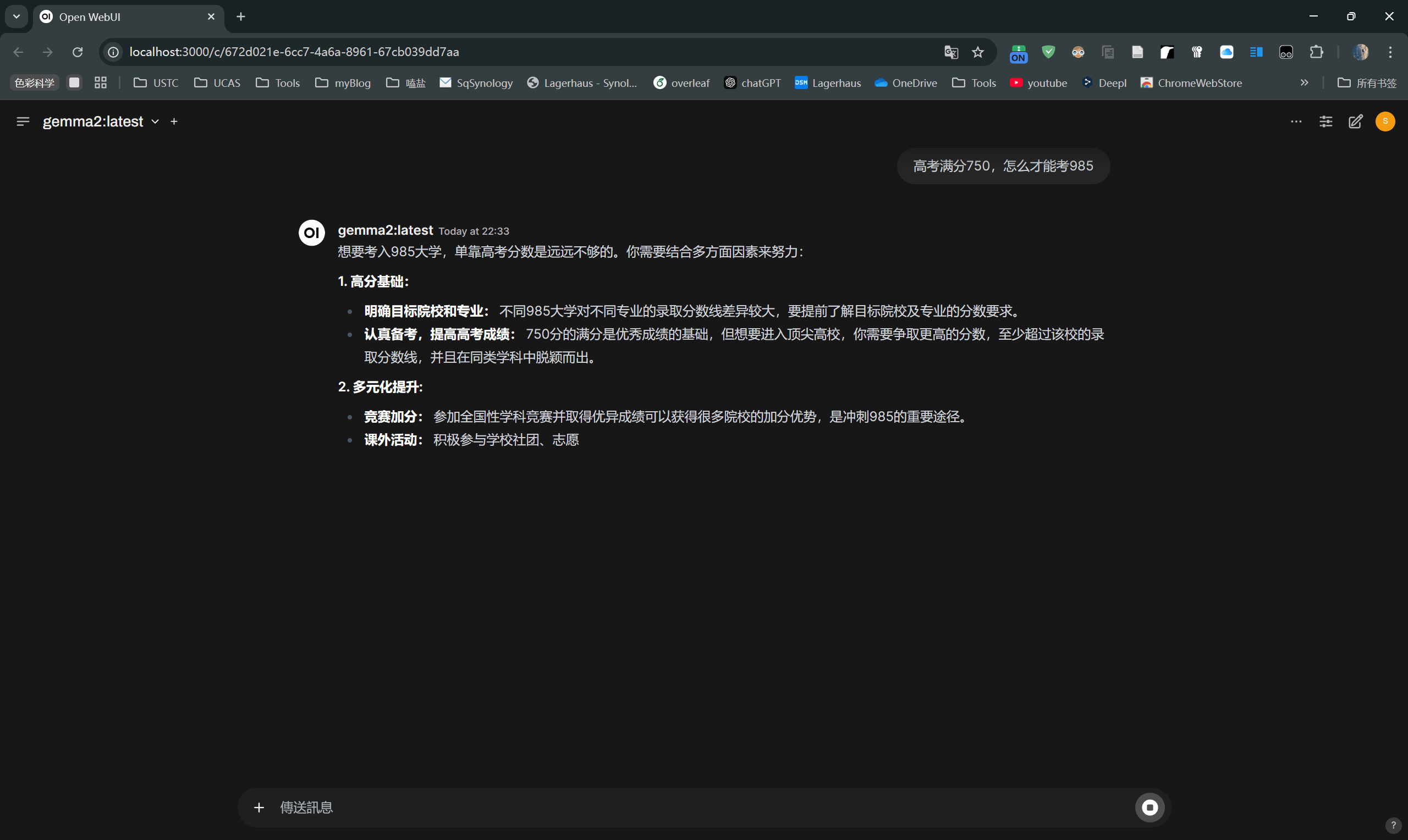
可以同时运行多个模型,换deepseek试试,听说它使用了弱智吧的数据集
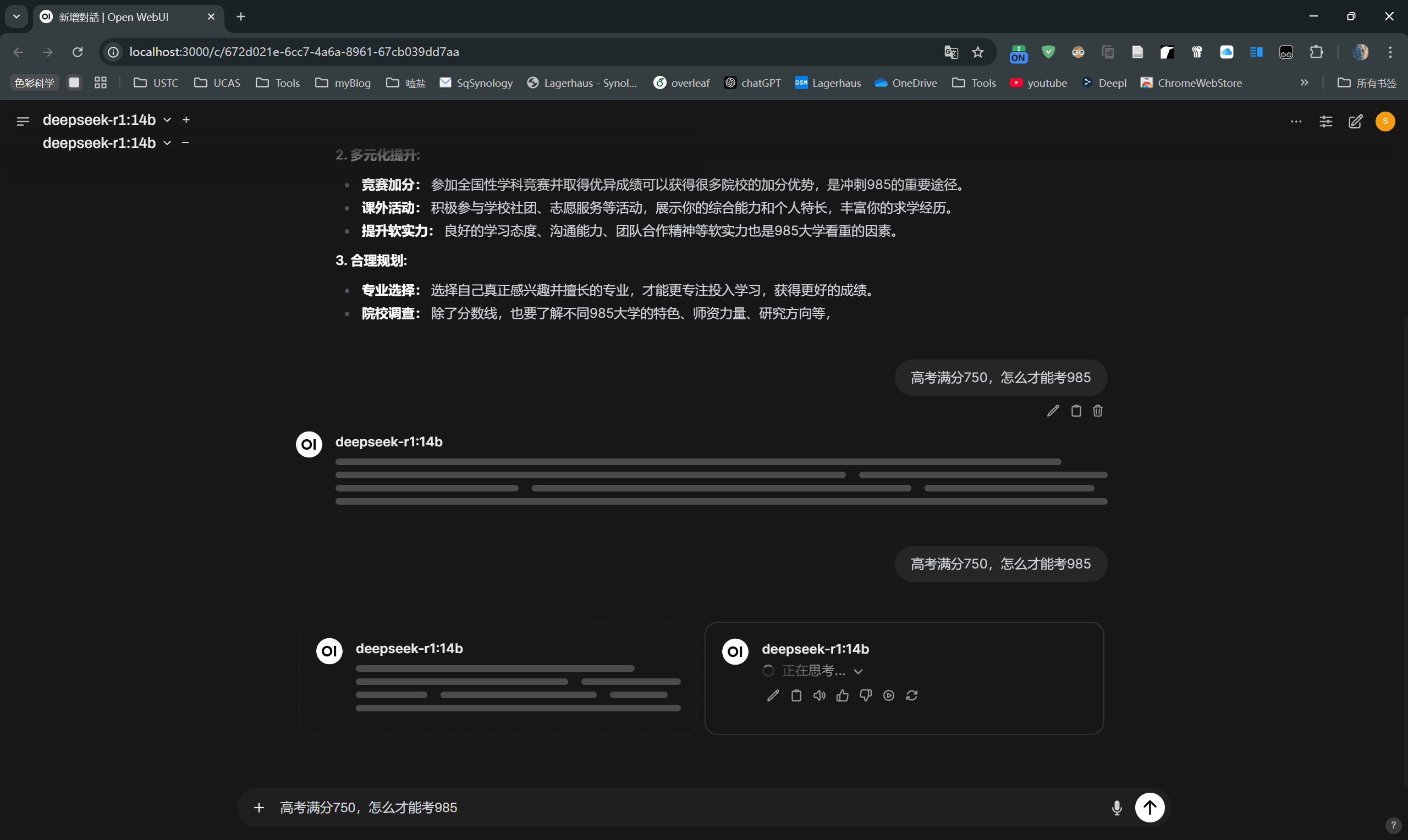
同时运行多个模型,风扇拼尽全力无法战胜
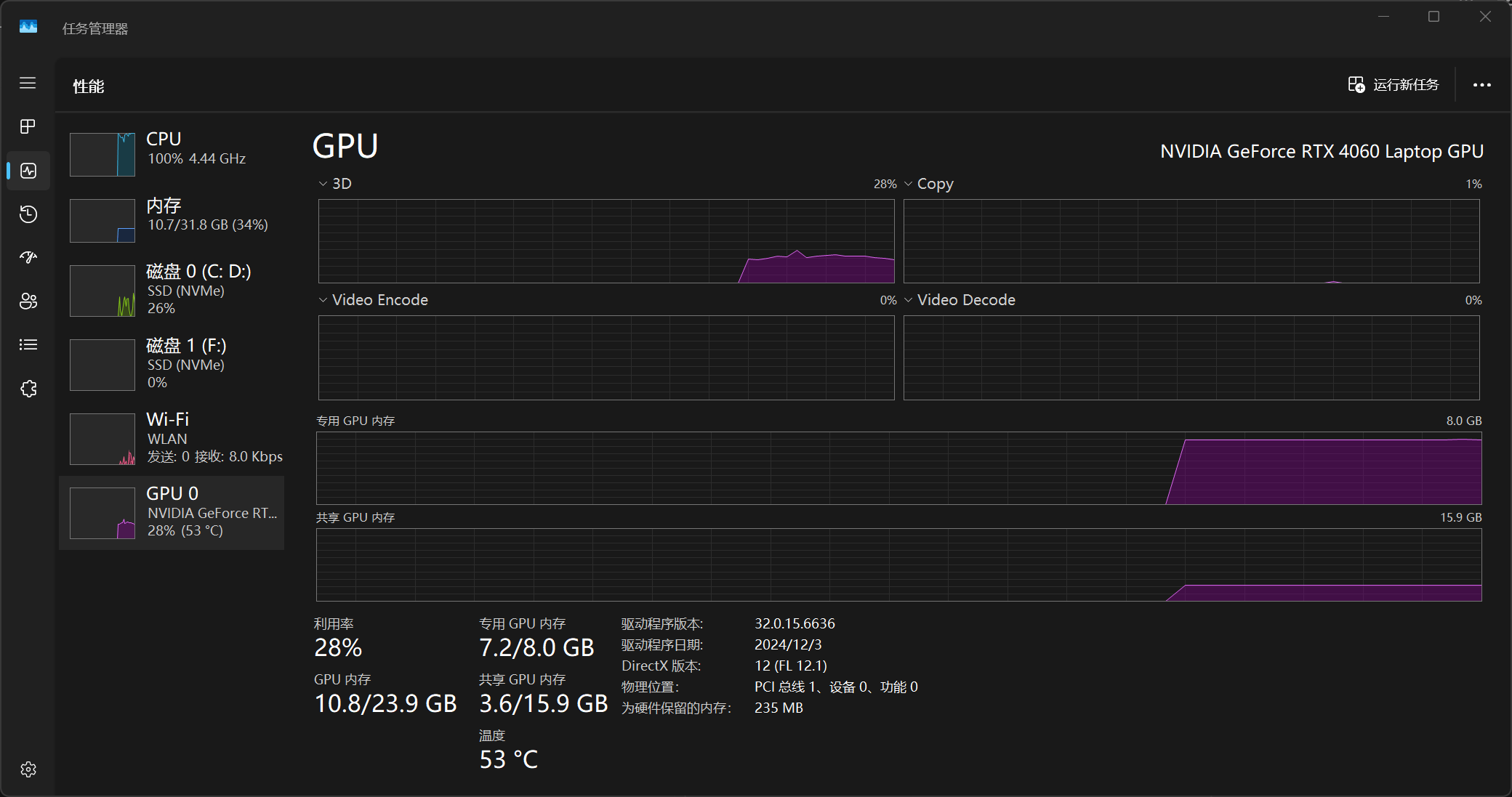
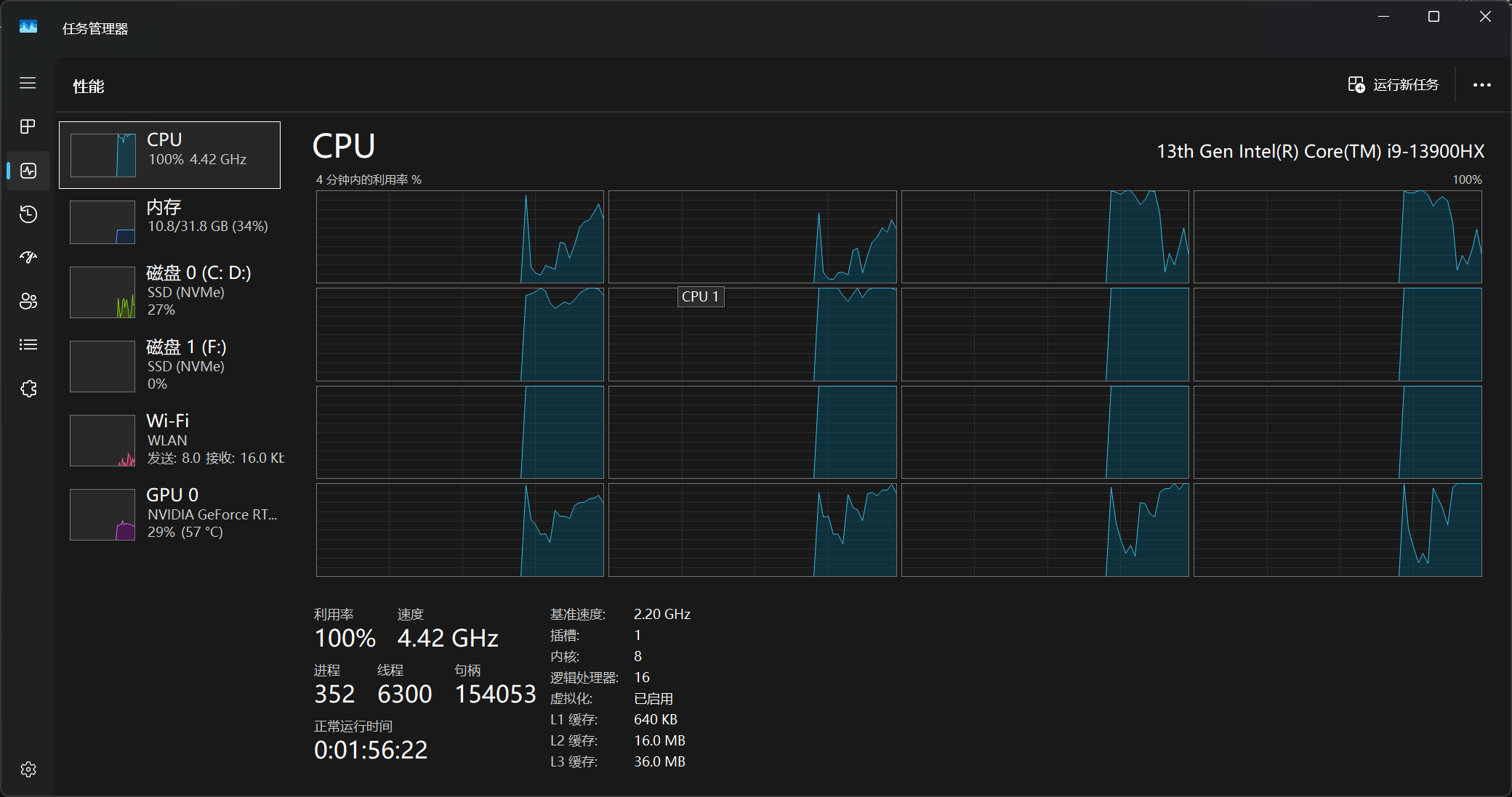
我的处理器是臭名昭著的13代酷睿,需要手动在BIOS中关闭E核避免调度问题
CPU满载的情况还是第一次见🤔
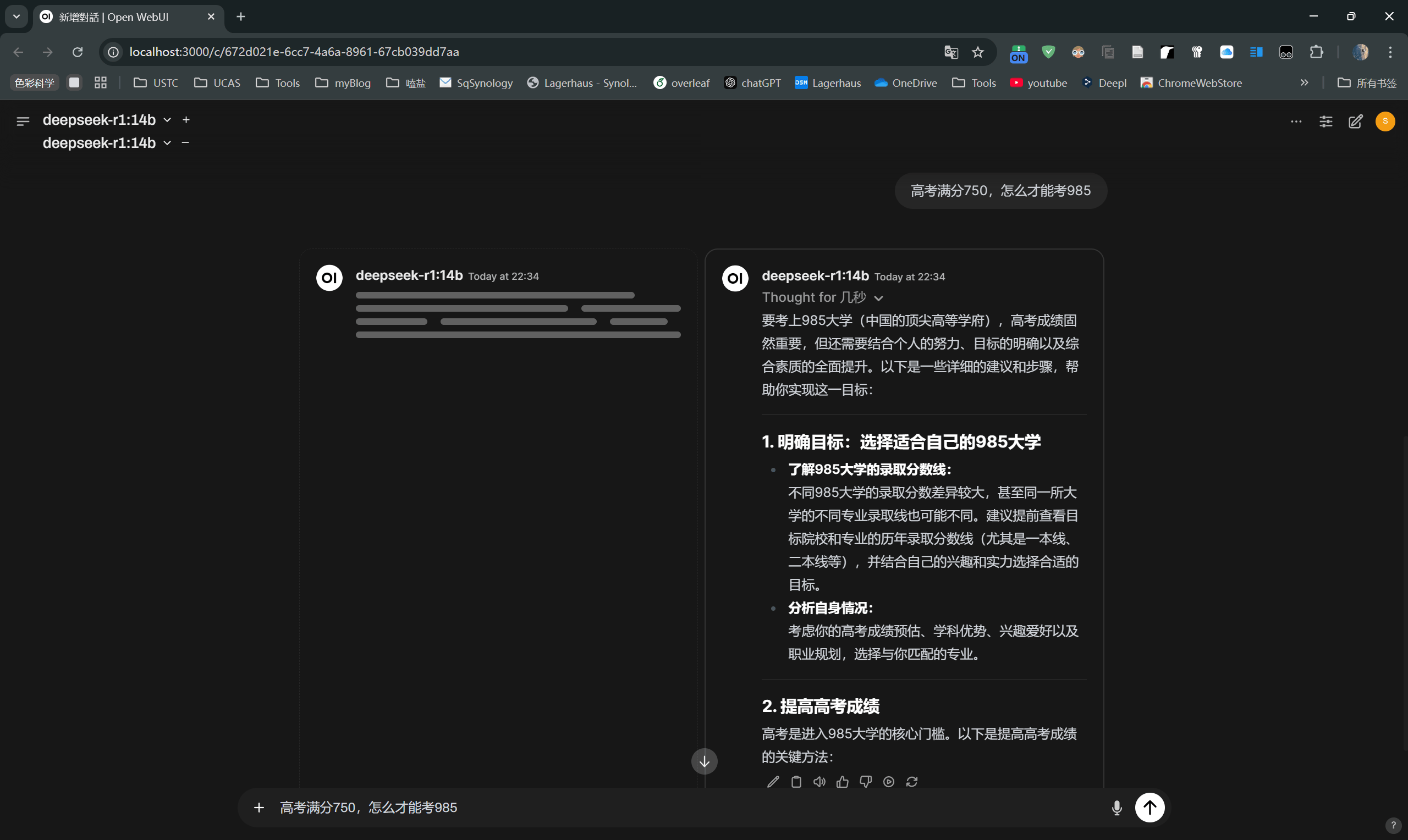
好吧DeepSeek也没聪明到哪去,这还是14b的版本
以上
题外话
哎呦卧槽太有节目效果了
刚刚发现我的chatGPT账号和Claude账号都被封了
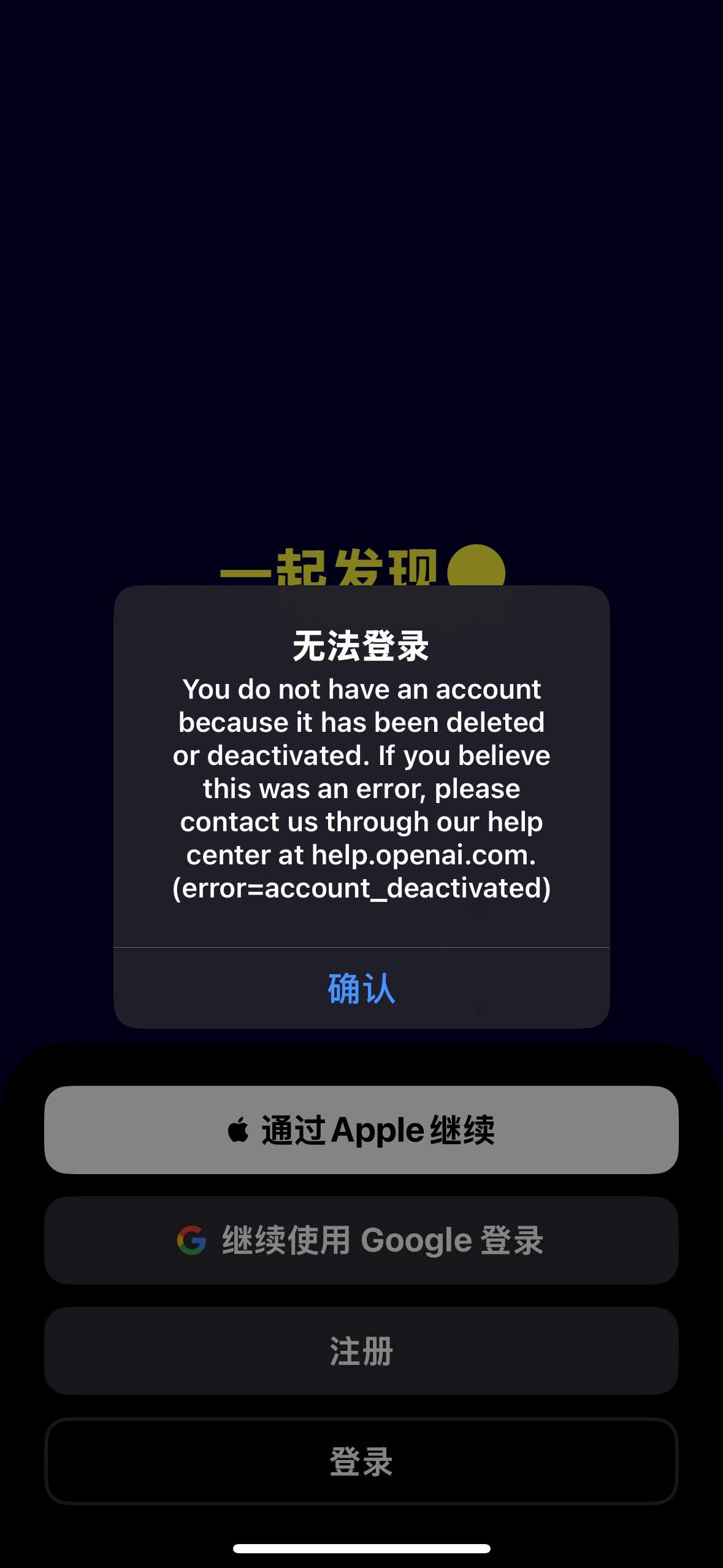
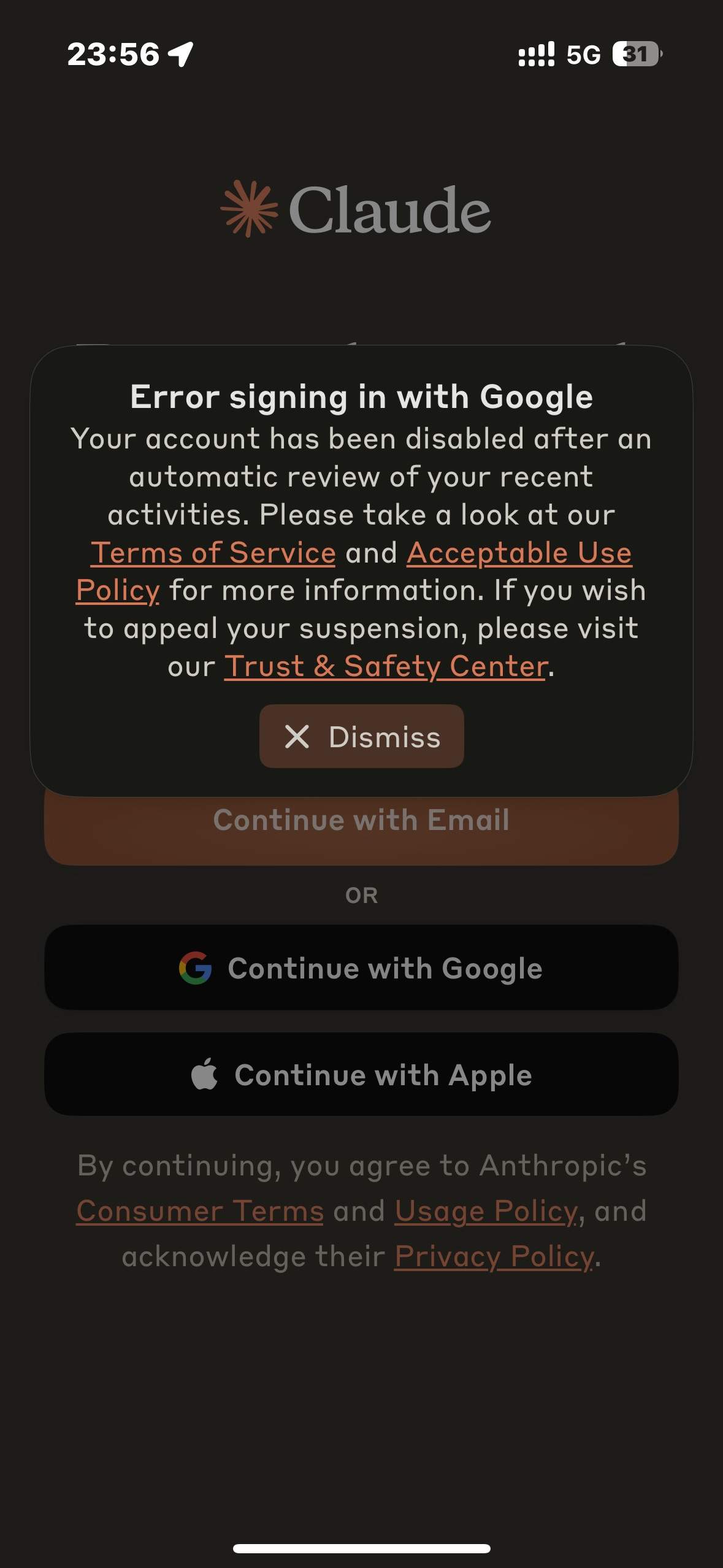
我明明上午还在用的啊
chatGPT账号注册一年多了快?每个月都冲plus会员,和Claude账号一样都绑定了Google账户,梯子的节点也干净
我没话说🤷
结语
希望这篇文章对你有帮助,任何疑问可以通过strtus@outlook.com与我联络
enjoy😉 !